GIS工具
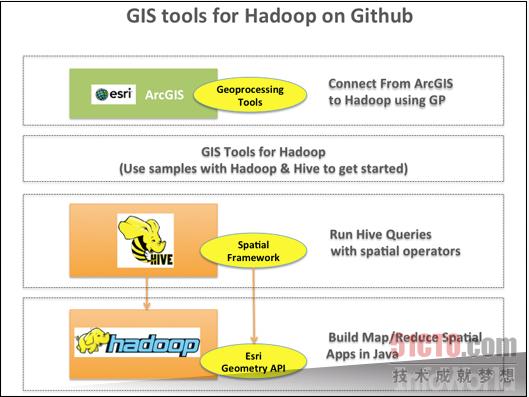
咱们生活的世界相当广阔,因此让运行Hadoop的集群与地理地图协作也是项难度很高的任务。针对Hadoop项目的GIS(即地理信息系统)工具采用多种基于Java的最佳工具,能够透彻理解地理信息并使其与Hadoop共同运行。我们的数据库将通过坐标而非字符串来处理地理查询,我们的代码则通过部署GIS工具来计算三维空间。有了GIS工具的帮助,大家面临的最大难题只剩下正确解读"map"这个词--它到底代表的是象征整个世界的平面图形,还是Hadoop作业当中的第一步、也就是"映射"? 上图所示为说明文档中关于这些工具的不同层级。目前这些工具可在GitHub上进行下载。 下载地址:http://esri.github.io/gis-tools-for-hadoop/ Flume
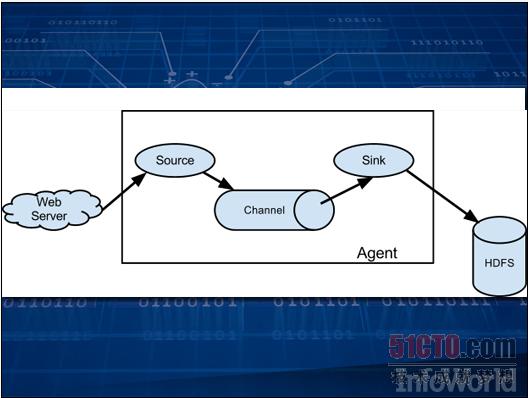
数据收集这项任务绝对不比数据存储或者数据分析更轻松。作为又一个Apache项目,Flume能够通过分派"代理"以收集信息并将结果保存在HDFS当中。每一个代理可以收集日志文件、调用Twitter API或者提取网站数据。这些代理由事件触发,而且可以被链接在一起。由此获得的数据随后即可供分析使用。 Flume项目的代码受Apache许可保护。 官方网站:flume.apache.org Hadoop上的SQL
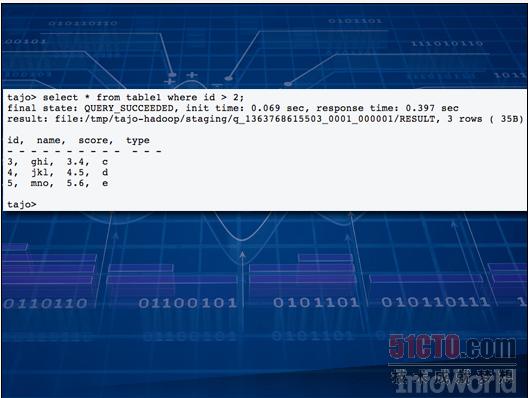
如果大家希望在自己的大型集群当中对全部数据来一次快速的临时性查询,正常来说需要编写一个新的Hadoop作业,这自然要花上一些时间。过去程序员们多次掉进过这同一个坑里,于是大家开始怀念老式SQL数据库--利用相对简单的SQL语言,我们就能为问题找到答案。从这一思路出发,众多公司开发出一系列新兴工具,这些方案全部指向更为快捷的应答途径。 其中最引人注目的方案包括:HAWQ、Impalla、Drill、Stinger以及Tajo。此类方案数量众多,足够另开一个全新专题。
很多云平台都在努力吸引Hadoop作业,这是因为其按分钟计算租金的灵活业务模式非常适合Hadoop的实际需求。企业可以在短时间内动用数千台设备进行大数据处理,而不必再像过去那样永久性购入机架、再花上几天或者几周时间执行同样的计算任务。某些企业,例如Amazon,正在通过将JAR文件引入软件规程添加新的抽象层。一切其它设置与调度工作都可由云平台自行完成。 上图所示为Martin Abegglen在Flickr上发表的几台刀片计算机。 Spark
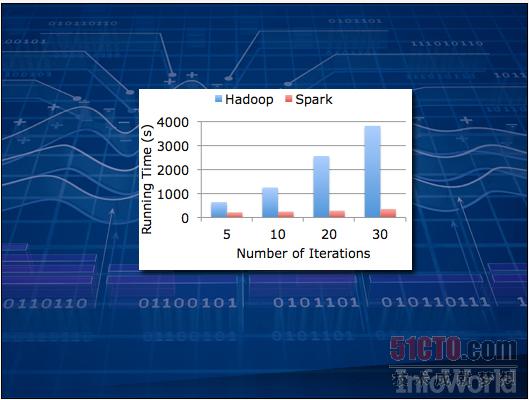
未来已然到来。对于某些算法,Hadoop的处理速度可能慢得令人抓狂--这是因为它通常依赖于存储在磁盘上的数据。对于日志文件这种只需读取一次的处理任务来说,速度慢些似乎还可以忍受;但一旦把范围扩大到所有负载,那些需要一次又一次访问数据的人工智能类程序可能因为速度过慢而根本不具备实用价值。 Spark代表着下一代解决思路。它与Hadoop的工作原理相似,但面向的却是保存在内存缓存中的数据。上图来自Apache说明文档,其中演示的是Spark在理想状态下与Hadoop之间的处理速度对比。 Spark项目正处于Apache开发当中。 官方网站:spark.incubator.apache.org 原文链接:http://www.infoworld.com/slideshow/131105/18-essential-hadoop-tools-crunching-big-data-232123#slide1 |











 /1
/1 

