当我们在生产线上用一台服务器来提供数据服务的时候,我会遇到如下的两个问题: 1)一台服务器的性能不足以提供足够的能力服务于所有的网络请求。 2)我们总是害怕我们的这台服务器停机,造成服务不可用或是数据丢失。 于是我们不得不对我们的服务器进行扩展,加入更多的机器来分担性能上的问题,以及来解决单点故障问题。 通常,我们会通过两种手段来扩展我们的数据服务: 1)数据分区:就是把数据分块放在不同的服务器上(如:uid % 16,一致性哈希等)。 2)数据镜像:让所有的服务器都有相同的数据,提供相当的服务。 对于第一种情况,我们无法解决数据丢失的问题,单台服务器出问题时,会有部分数据丢失。所以,数据服务的高可用性只能通过第二种方法来完成——数据的冗余存储(一般工业界认为比较安全的备份数应该是3份,如:Hadoop和Dynamo)。 但是,加入更多的机器,会让我们的数据服务变得很复杂,尤其是跨服务器的事务处理,也就是跨服务器的数据一致性。这个是一个很难的问题。 让我们用最经典的Use Case:“A帐号向B帐号汇钱”来说明一下,熟悉RDBMS事务的都知道从帐号A到帐号B需要6个操作:
为了数据的一致性,这6件事,要么都成功做完,要么都不成功,而且这个操作的过程中,对A、B帐号的其它访问必需锁死,所谓锁死就是要排除其它的读写操作,不然会有脏数据的问题,这就是事务。那么,我们在加入了更多的机器后,这个事情会变得复杂起来: 1)在数据分区的方案中:如果A帐号和B帐号的数据不在同一台服务器上怎么办?我们需要一个跨机器的事务处理。也就是说,如果A的扣钱成功了,但B的加钱不成功,我们还要把A的操作给回滚回去。这在跨机器的情况下,就变得比较复杂了。 2)在数据镜像的方案中:A帐号和B帐号间的汇款是可以在一台机器上完成的,但是别忘了我们有多台机器存在A帐号和B帐号的副本。如果对A帐号的汇钱有两个并发操作(要汇给B和C),这两个操作发生在不同的两台服务器上怎么办?也就是说,在数据镜像中,在不同的服务器上对同一个数据的写操作怎么保证其一致性,保证数据不冲突? 同时,我们还要考虑性能的因素,如果不考虑性能的话,事务得到保证并不困难,系统慢一点就行了。除了考虑性能外,我们还要考虑可用性,也就是说,一台机器没了,数据不丢失,服务可由别的机器继续提供。 于是,我们需要重点考虑下面的这么几个情况: 1)容灾:数据不丢、结点的Failover 2)数据的一致性:事务处理 3)性能:吞吐量 、 响应时间 前面说过,要解决数据不丢,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本:当出现某个节点的数据丢失时可以从副本读到,数据副本是分布式系统解决数据丢失异常的唯一手段。所以,在这篇文章中,简单起见,我们只讨论在数据冗余情况下考虑数据的一致性和性能的问题。简单说来: 1)要想让数据有高可用性,就得写多份数据。 2)写多份的问题会导致数据一致性的问题。 3)数据一致性的问题又会引发性能问题 这就是软件开发,按下了葫芦起了瓢。 一致性模型说起数据一致性来说,简单说有三种类型(当然,如果细分的话,还有很多一致性模型,如:顺序一致性,FIFO一致性,会话一致性,单读一致性,单写一致性,但为了本文的简单易读,我只说下面三种): 1)Weak 弱一致性:当你写入一个新值后,读操作在数据副本上可能读出来,也可能读不出来。比如:某些cache系统,网络游戏其它玩家的数据和你没什么关系,VOIP这样的系统,或是百度搜索引擎(呵呵)。 2)Eventually 最终一致性:当你写入一个新值后,有可能读不出来,但在某个时间窗口之后保证最终能读出来。比如:DNS,电子邮件、Amazon S3,Google搜索引擎这样的系统。 3)Strong 强一致性:新的数据一旦写入,在任意副本任意时刻都能读到新值。比如:文件系统,RDBMS,Azure Table都是强一致性的。 从这三种一致型的模型上来说,我们可以看到,Weak和Eventually一般来说是异步冗余的,而Strong一般来说是同步冗余的,异步的通常意味着更好的性能,但也意味着更复杂的状态控制。同步意味着简单,但也意味着性能下降。 好,让我们由浅入深,一步一步地来看有哪些技术: Master-Slave首先是Master-Slave结构,对于这种加构,Slave一般是Master的备份。在这样的系统中,一般是如下设计的: 1)读写请求都由Master负责。 2)写请求写到Master上后,由Master同步到Slave上。 从Master同步到Slave上,你可以使用异步,也可以使用同步,可以使用Master来push,也可以使用Slave来pull。 通常来说是Slave来周期性的pull,所以,是最终一致性。这个设计的问题是,如果Master在pull周期内垮掉了,那么会导致这个时间片内的数据丢失。如果你不想让数据丢掉,Slave只能成为Read-Only的方式等Master恢复。 当然,如果你可以容忍数据丢掉的话,你可以马上让Slave代替Master工作(对于只负责计算的结点来说,没有数据一致性和数据丢失的问题,Master-Slave的方式就可以解决单点问题了) 当然,Master Slave也可以是强一致性的, 比如:当我们写Master的时候,Master负责先写自己,等成功后,再写Slave,两者都成功后返回成功,整个过程是同步的,如果写Slave失败了,那么两种方法,一种是标记Slave不可用报错并继续服务(等Slave恢复后同步Master的数据,可以有多个Slave,这样少一个,还有备份,就像前面说的写三份那样),另一种是回滚自己并返回写失败。(注:一般不先写Slave,因为如果写Master自己失败后,还要回滚Slave,此时如果回滚Slave失败,就得手工订正数据了)你可以看到,如果Master-Slave需要做成强一致性有多复杂。 Master-MasterMaster-Master,又叫Multi-master,是指一个系统存在两个或多个Master,每个Master都提供read-write服务。这个模型是Master-Slave的加强版,数据间同步一般是通过Master间的异步完成,所以是最终一致性。 Master-Master的好处是,一台Master挂了,别的Master可以正常做读写服务,他和Master-Slave一样,当数据没有被复制到别的Master上时,数据会丢失。很多数据库都支持Master-Master的Replication的机制。 另外,如果多个Master对同一个数据进行修改的时候,这个模型的恶梦就出现了——对数据间的冲突合并,这并不是一件容易的事情。看看Dynamo的Vector Clock的设计(记录数据的版本号和修改者)就知道这个事并不那么简单,而且Dynamo对数据冲突这个事是交给用户自己搞的。就像我们的SVN源码冲突一样,对于同一行代码的冲突,只能交给开发者自己来处理。(在本文后后面会讨论一下Dynamo的Vector Clock) Two/Three Phase Commit这个协议的缩写又叫2PC,中文叫两阶段提交。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。 两阶段提交的算法如下: 第一阶段:
第二阶段:
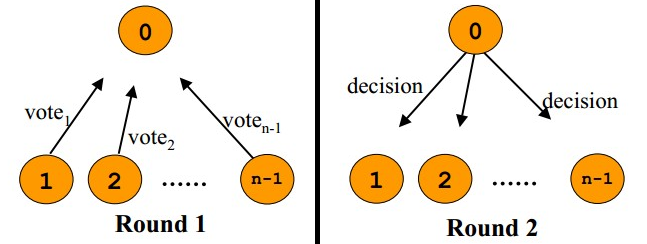
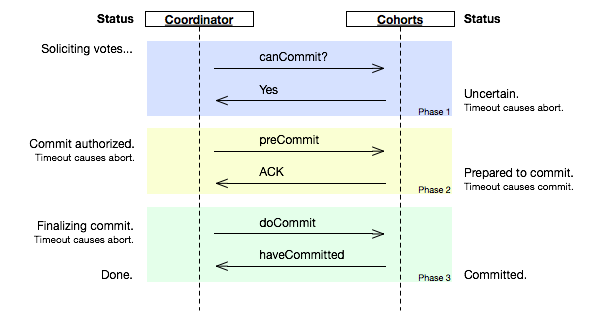
我们可以看到,2PC说白了就是第一阶段做Vote,第二阶段做决定的一个算法,也可以看到2PC这个事是强一致性的算法。在前面我们讨论过Master-Slave的强一致性策略,和2PC有点相似,只不过2PC更为保守一些——先尝试再提交。 2PC用的是比较多的,在一些系统设计中,会串联一系列的调用,比如:A -> B -> C -> D,每一步都会分配一些资源或改写一些数据。比如我们B2C网上购物的下单操作在后台会有一系列的流程需要做。如果我们一步一步地做,就会出现这样的问题,如果某一步做不下去了,那么前面每一次所分配的资源需要做反向操作把他们都回收掉,所以,操作起来比较复杂。现在很多处理流程(Workflow)都会借鉴2PC这个算法,使用 try -> confirm的流程来确保整个流程的能够成功完成。 举个通俗的例子,西方教堂结婚的时候,都有这样的桥段: 1)牧师分别问新郎和新娘:你是否愿意……不管生老病死……(询问阶段) 2)当新郎和新娘都回答愿意后(锁定一生的资源),牧师就会说:我宣布你们……(事务提交) 这是多么经典的一个两阶段提交的事务处理。 另外,我们也可以看到其中的一些问题, A)其中一个是同步阻塞操作,这个事情必然会非常大地影响性能。 B)另一个主要的问题是在TimeOut上,比如, 1)如果第一阶段中,参与者没有收到询问请求,或是参与者的回应没有到达协调者。那么,需要协调者做超时处理,一旦超时,可以当作失败,也可以重试。 2)如果第二阶段中,正式提交发出后,如果有的参与者没有收到,或是参与者提交/回滚后的确认信息没有返回,一旦参与者的回应超时,要么重试,要么把那个参与者标记为问题结点剔除整个集群,这样可以保证服务结点都是数据一致性的。 3)糟糕的情况是,第二阶段中,如果参与者收不到协调者的commit/fallback指令,参与者将处于“状态未知”阶段,参与者完全不知道要怎么办,比如:如果所有的参与者完成第一阶段的回复后(可能全部yes,可能全部no,可能部分yes部分no),如果协调者在这个时候挂掉了。那么所有的结点完全不知道怎么办(问别的参与者都不行)。为了一致性,要么死等协调者,要么重发第一阶段的yes/no命令。 两段提交最大的问题就是第3)项,如果第一阶段完成后,参与者在第二阶没有收到决策,那么数据结点会进入“不知所措”的状态,这个状态会block住整个事务。也就是说,协调者Coordinator对于事务的完成非常重要,Coordinator的可用性是个关键。 因些,我们引入三段提交,三段提交在Wikipedia上的描述如下,他把二段提交的第一个段break成了两段:询问,然后再锁资源。最后真正提交。三段提交的示意图如下:
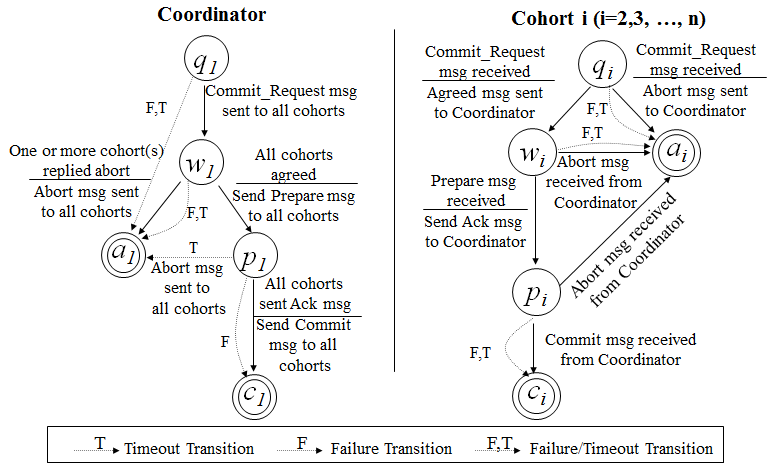
三段提交的核心理念是:在询问的时候并不锁定资源,除非所有人都同意了,才开始锁资源。 理论上来说,如果第一阶段所有的结点返回成功,那么有理由相信成功提交的概率很大。这样一来,可以降低参与者Cohorts的状态未知的概率。也就是说,一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了。这一点很重要。下面我们来看一下3PC的状态迁移图:(注意图中的虚线,那些F,T是Failuer或Timeout,其中的:状态含义是 q – Query,a – Abort,w – Wait,p – PreCommit,c – Commit)
从上图的状态变化图我们可以从虚线(那些F,T是Failuer或Timeout)看到——如果结点处在P状态(PreCommit)的时候发生了F/T的问题,三段提交比两段提交的好处是,三段提交可以继续直接把状态变成C状态(Commit),而两段提交则不知所措。 其实,三段提交是一个很复杂的事情,实现起来相当难,而且也有一些问题。 看到这里,我相信你有很多很多的问题,你一定在思考2PC/3PC中各种各样的失败场景,你会发现Timeout是个非常难处理的事情,因为网络上的Timeout在很多时候让你无所事从,你也不知道对方是做了还是没有做。于是你好好的一个状态机就因为Timeout成了个摆设。 一个网络服务会有三种状态:1)Success,2)Failure,3)Timeout,第三个绝对是恶梦,尤其在你需要维护状态的时候。 |
最新评论
最新新闻










 /1
/1 

