|
百度作为全球最大的中文搜索引擎公司,提供基于搜索引擎的各种产品,包括以网络搜索为主的功能性搜索;以贴吧为主的社区搜索;针对区域、行业的垂直搜索、MP3音乐搜索,以及百科等,几乎覆盖了中文网络世界中所有的搜索需求。 百度对海量数据处理的要求是比较高的,要在线下对数据进行分析,还要在规定的时间内处理完并反馈到平台上。百度在互联网领域的平台需求如图3-3所示,这里就需要通过性能较好的云平台进行处理了,Hadoop就是很好的选择。在百度,Hadoop主要应用于以下几个方面: ·日志的存储和统计; ·网页数据的分析和挖掘; ·商业分析,如用户的行为和广告关注度等; ·在线数据的反馈,及时得到在线广告的点击情况; ·用户网页的聚类,分析用户的推荐度及用户之间的关联度。 MapReduce主要是一种思想,不能解决所有领域内与计算有关的问题,百度的研究人员认为比较好的模型应该如下图所示,HDFS实现共享存储,一些计算使用MapReduce解决,一些计算使用MPI解决,而还有一些计算需要通过两者来共同处理。因为MapReduce适合处理数据很大且适合划分的数据,所以在处理这类数据时就可以用MapReduce做一些过滤,得到基本的向量矩阵,然后通过MPI进一步处理后返回结果,只有整合技术才能更好地解决问题。 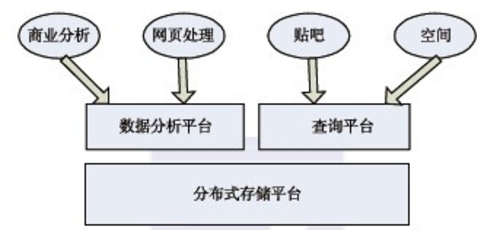
▲互联网领域的平台需求
百度现在拥有3个Hadoop集群,总规模在700台机器左右,其中有100多台新机器和600多台要淘汰的机器(它们的计算能力相当于200多台新机器),不过其规模还在不断的增加中。现在每天运行的MapReduce任务在3000个左右,处理数据约120TB/天。 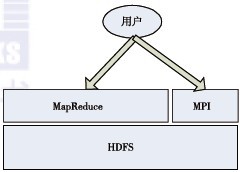
▲计算模型
百度为了更好地用Hadoop进行数据处理,在以下几个方面做了改进和调整: (1)调整MapReduce策略 ·限制作业处于运行状态的任务数; ·调整预测执行策略,控制预测执行量,一些任务不需要预测执行; ·根据节点内存状况进行调度; ·平衡中间结果输出,通过压缩处理减少I/O负担。 (2)改进HDFS的效率和功能 ·权限控制,在PB级数据量的集群上数据应该是共享的,这样分析起来比较容易,但是需要对权限进行限制; ·让分区与节点独立,这样,一个分区坏掉后节点上的其他分区还可以正常使用; ·修改DFSClient选取块副本位置的策略,增加功能使DFSClient选取块时跳过出错的DataNode; ·解决VFS(Virtual File System)的POSIX(Portable Operating System Interface of Unix)兼容性问题。 (3)修改Speculative的执行策略 ·采用速率倒数替代速率,防止数据分布不均时经常不能启动预测执行情况的发生; ·增加任务时必须达到某个百分比后才能启动预测执行的限制,解决reduce运行等待map数据的时间问题; ·只有一个map或reduce时,可以直接启动预测执行。 (4)对资源使用进行控制 ·对应用物理内存进行控制。如果内存使用过多会导致操作系统跳过一些任务,百度通过修改Linux内核对进程使用的物理内存进行独立的限制,超过阈值可以终止进程。 ·分组调度计算资源,实现存储共享、计算独立,在Hadoop中运行的进程是不可抢占的。 ·在大块文件系统中,X86平台下一个页的大小是4KB。如果页较小,管理的数据就会很多,会增加数据操作的代价并影响计算效率,因此需要增加页的大小。 百度在使用Hadoop时也遇到了一些问题,主要有: ·MapReduce的效率问题:比如,如何在shuffle效率方面减少I/O次数以提高并行效率;如何在排序效率方面设置排序为可配置的,因为排序过程会浪费很多的计算资源,而一些情况下是不需要排序的。 ·HDFS的效率和可靠性问题:如何提高随机访问效率,以及数据写入的实时性问题,如果Hadoop每写一条日志就在HDFS上存储一次,效率会很低。 ·内存使用的问题:reducer端的shuffle会频繁地使用内存,这里采用类似Linux的buddy system来解决,保证Hadoop用最小的开销达到最高的利用率;当Java 进程内容使用内存较多时,可以调整垃圾回收(GC)策略;有时存在大量的内存复制现象,这会消耗大量CPU资源,同时还会导致内存使用峰值极高,这时需要减少内存的复制。 ·作业调度的问题:如何限制任务的map和reduce计算单元的数量,以确保重要计算可以有足够的计算单元;如何对TaskTracker进行分组控制,以限制作业执行的机器,同时还可以在用户提交任务时确定执行的分组并对分组进行认证。 ·性能提升的问题:UserLogs cleanup在每次task结束的时候都要查看一下日志,以决定是否清除,这会占用一定的任务资源,可以通过将清理线程从子Java进程移到TaskTracker来解决;子Java进程会对文本行进行切割而map和reduce进程则会重新切割,这将造成重复处理,这时需要关掉Java进程的切割功能;在排序的时候也可以实现并行排序来提升性能;实现对数据的异步读写也可以提升性能。 ·健壮性的问题:需要对mapper和reducer程序的内存消耗进行限制,这就要修改Linux内核,增加其限制进程的物理内存的功能;也可以通过多个map程序共享一块内存,以一定的代价减少对物理内存的使用;还可以将DataNode和TaskTracker的UGI配置为普通用户并设置账号密码;或者让DataNode和TaskTracker分账号启动,确保HDFS数据的安全性,防止Tracker操作DataNode中的内容;在不能保证用户的每个程序都很健壮的情况下,有时需要将进程终止掉,但要保证父进程终止后子进程也被终止。 ·Streaming局限性的问题:比如,只能处理文本数据,mapper和reducer按照文本行的协议通信,无法对二进制的数据进行简单处理。为了解决这个问题,百度人员新写了一个类Bistreaming(Binary Streaming),这里的子Java进程mapper和reducer按照(KeyLen,Key,ValLen,Value)的方式通信,用户可以按照这个协议编写程序。 ·用户认证的问题:这个问题的解决办法是让用户名、密码、所属组都在NameNode和Job Tracker上集中维护,用户连接时需要提供用户名和密码,从而保证数据的安全性。 百度下一步的工作重点可能主要会涉及以下内容: ·内存方面,降低NameNode的内存使用并研究JVM的内存管理; ·调度方面,改进任务可以被抢占的情况,同时开发出自己的基于Capacity的作业调度器,让等待作业队列具有优先级且队列中的作业可以设置Capacity,并可以支持TaskTracker分组; ·压缩算法,选择较好的方法提高压缩比、减少存储容量,同时选取高效率的算法以进行shuffle数据的压缩和解压; ·对mapper程序和reducer程序使用的资源进行控制,防止过度消耗资源导致机器死机。以前是通过修改Linux内核来进行控制的,现在考虑通过在Linux中引入cgroup来对mapper和reducer使用的资源进行控制; ·将DataNode的并发数据读写方式由多线程改为select方式,以支持大规模并发读写和Hypertable的应用。 百度同时也在使用Hypertable,它是以Google发布的BigTable为基础的开源分布式数据存储系统,百度将它作为分析用户行为的平台,同时在元数据集中化、内存占用优化、集群安全停机、故障自动恢复等方面做了一些改进。 | 
 发表于 2014-9-27 10:38:01
发表于 2014-9-27 10:38:01

