|
在使用 Apache Spark 的时候,作业会以分布式的方式在不同的节点上运行;特别是当集群的规模很大时,集群的节点出现各种问题是很常见的,比如某个磁盘出现问题等。我们都知道 Apache Spark 是一个高性能、容错的分布式计算框架,一旦它知道某个计算所在的机器出现问题(比如磁盘故障),它会依据之前生成的 lineage 重新调度这个 Task。
我们现在来考虑下下面的场景:
1、有个节点上的磁盘由于某些原因出现间歇性故障,导致某些扇区不能被读取。假设我们的 Spark 作业需要的数据正好就在这些扇区上,这将会导致这个 Task 失败。
2、这个作业的 Driver 获取到这个信息,知道 Task 失败了,所以它会重新提交这个 Task。
3、Scheduler 获取这个请求之后,它会考虑到数据的本地性问题,所以很可能还是把这个 Task 分发到上述的机器,因为它并不知道上述机器的磁盘出现了问题。
4、因为这个机器的磁盘出现问题,所以这个 Task 可能一样失败。然后 Driver 重新这些操作,最终导致了 Spark 作业出现失败!
上面提到的场景其实对我们人来说可以通过某些措施来避免。但是对于 Apache Spark 2.2.0 版本之前是无法避免的,不过高兴的是,来自 Cloudera 的工程师解决了这个问题:引入了黑名单机制 Blacklist(详情可以参见SPARK-8425,具体的设计文档参见Design Doc for Blacklist Mechanism),并且随着 Apache Spark 2.2.0 版本发布,不过目前还处于实验性阶段。 黑名单机制其实是通过维护之前出现问题的执行器(Executors)和节点(Hosts)的记录。当某个任务(Task)出现失败,那么黑名单机制将会追踪这个任务关联的执行器以及主机,并记下这些信息;当在这个节点调度任务出现失败的次数超过一定的数目(默认为2),那么调度器将不会再将任务分发到那台节点。调度器甚至可以杀死那台机器对应的执行器,这些都可以通过相应的配置实现。 我们可以通过 Apache Spark WEB UI 界面看到执行器的状态(Status):如果执行器处于黑名单状态,你可以在页面上看到其状态为 Blacklisted ,否则为 Active。如下图所示: 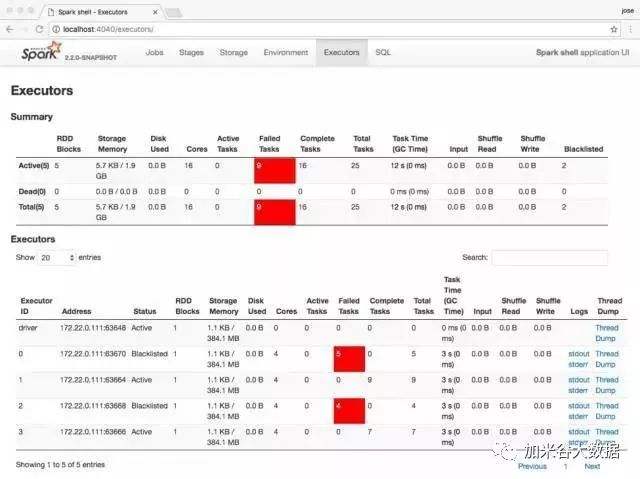 拥有了黑名单机制之后,上面场景的问题就可以很好的解决。 目前黑名单机制可以通过一系列的参数来控制,主要如下: 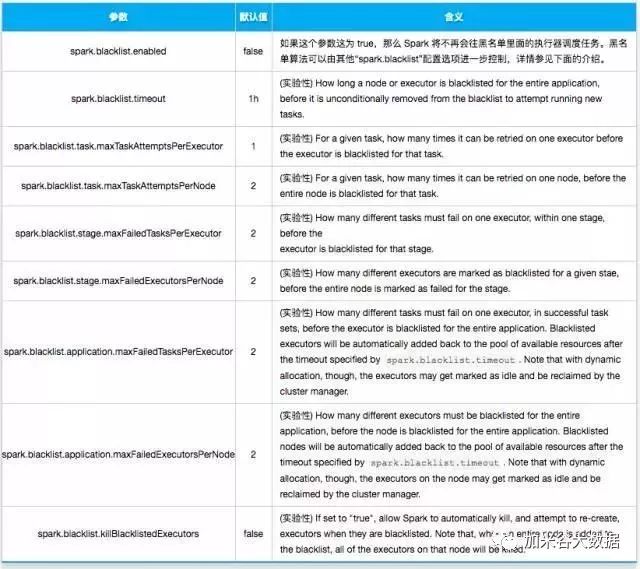 因为黑名单机制目前还处于实验性状态,所以上面的一些参数可能会在后面的 Spark 中有所修改。  成都加米谷大数据科技有限公司是一家专注于大数据人才培养的机构。由来自阿里、华为、京东、星环等国内知名企业的多位技术大牛联合创办,技术底蕴丰厚,勤奋创新,精通主流前沿大数据及人工智能相关技术。
以国家规划大数据产业发展战略为指引,以全国大数据技术和大 数据分析人才的培养为使命,以提升就业能力、强化职业技术为目标。面向社会提供大数据、人工智能等前沿技术的培训业务。  更 多 精 彩
加 米 谷 大 数 据
| 
 发表于 2017-12-27 17:59:33
发表于 2017-12-27 17:59:33

