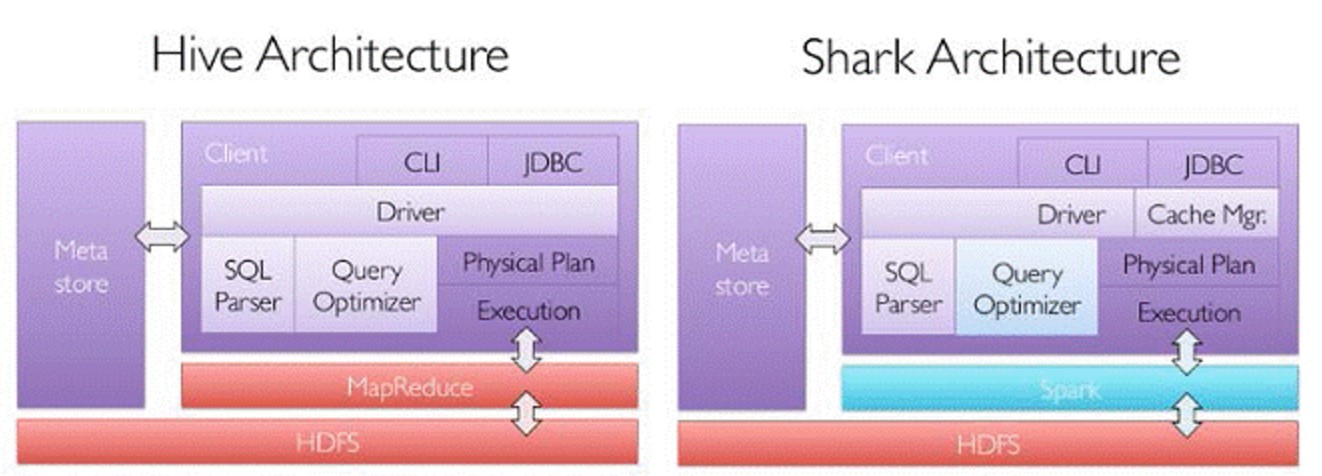
1.hive vs spark-sql#为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率底,spark sql而是采用内存存储可以减少大量的中间磁盘落地数据。相比hive速度能提高10到100倍。
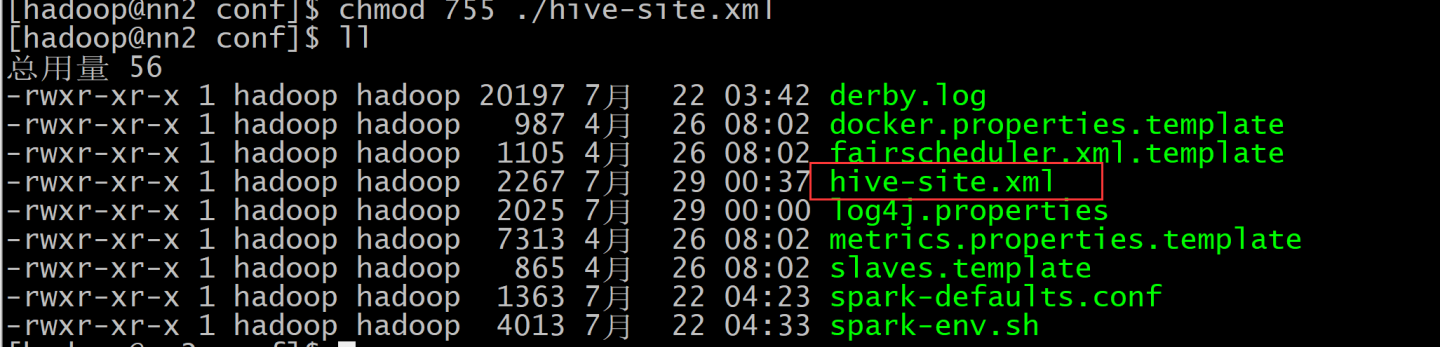
2.集群配置#拷贝hive的配置文件到spark conf的目录下,并删除不必要的信息,增加thrift server配置
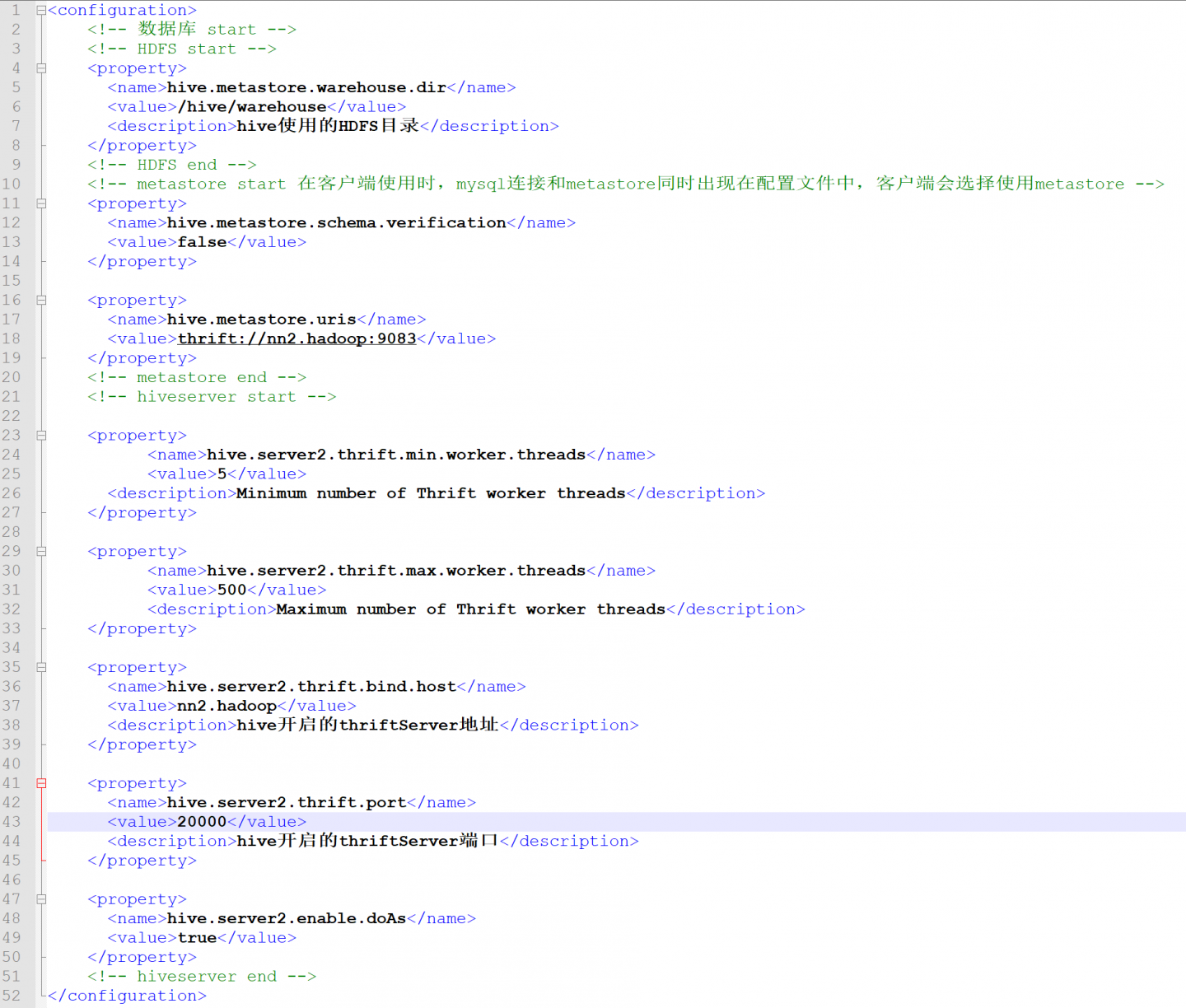
修改conf/hive-site.xml 中的 “hive.metastore.schema.verification”值为false即可解决 “Caused by: MetaException(message:Version information not found in metastore.)
减少日志输出

spark-env.sh

spark-defaults.conf,yarn模式运行所需要的Libs
/usr/local/spark/jars

3.spark-sql#这种方式每个人一个driver彼此之间的数据无法共享
spark-sql --master yarn --queue hainiu --num-executors 12 --executor-memory 5G

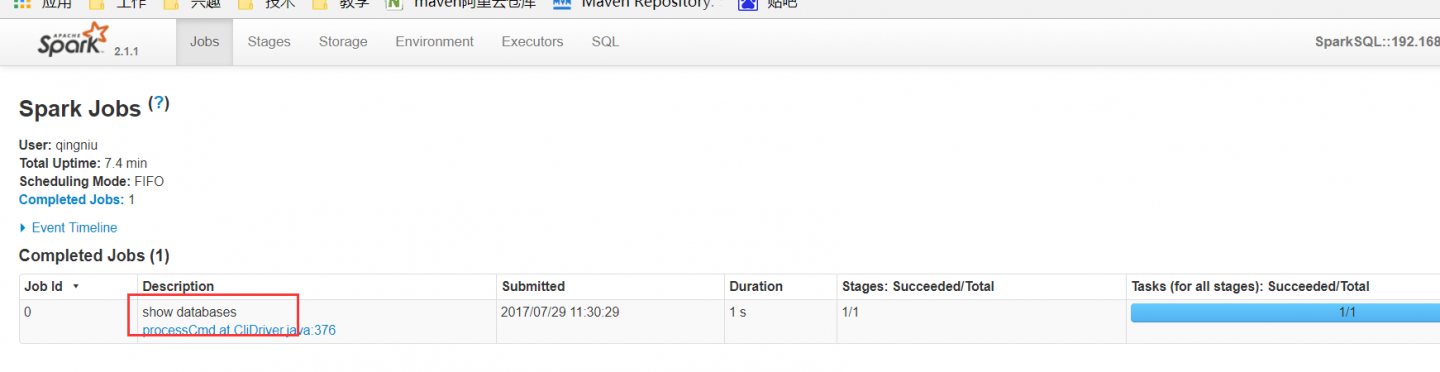
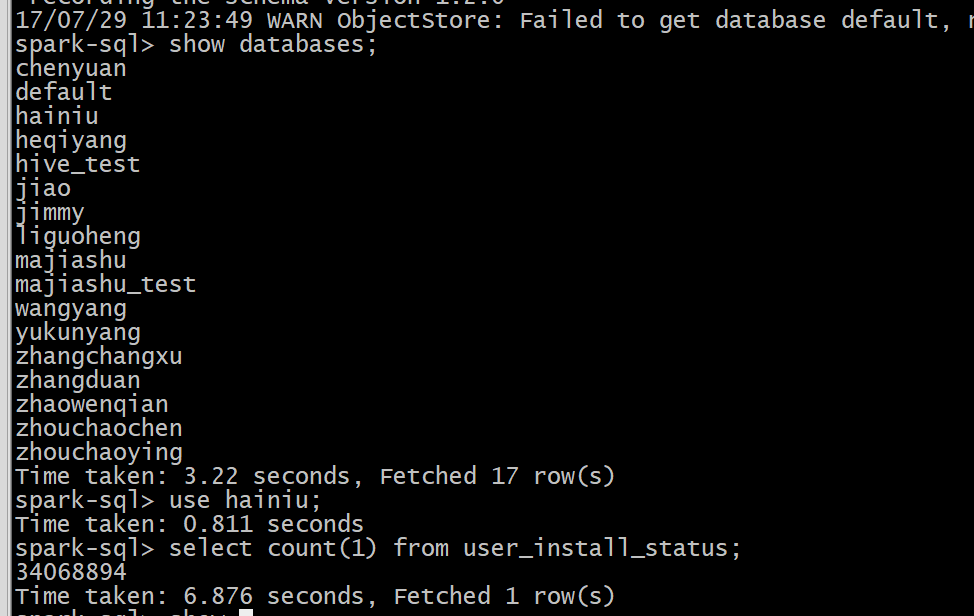
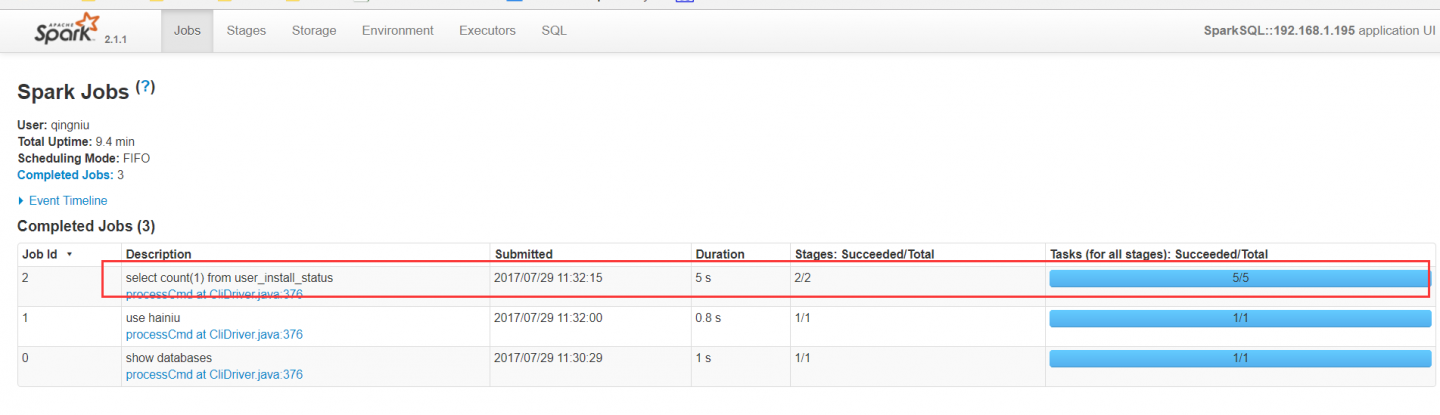

默认的任务partitions为200

SET spark.sql.shuffle.partitions=20;
可以减少shuffle的次数


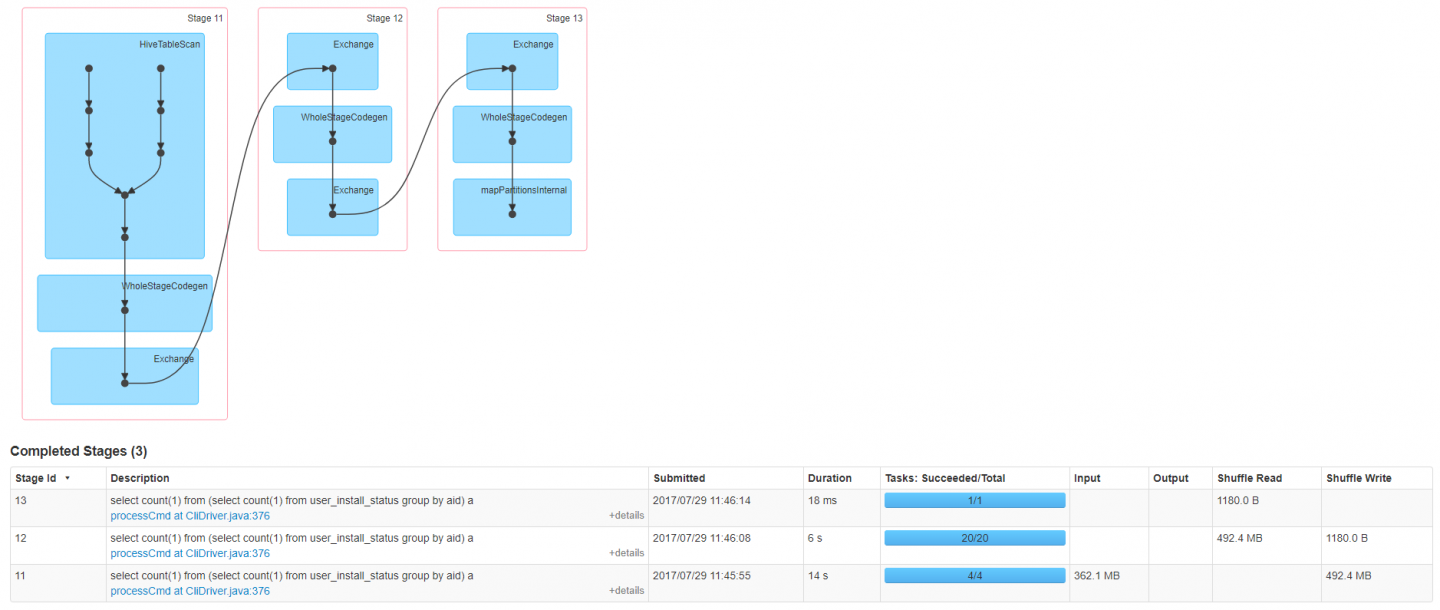
spark-sql --help可以查看CLI命令参数:
4.spart thriftserver#这种方式所有人可以连接driver彼此之间的数据可以共享
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个SparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个SparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用Hive数据的话,还要提供Hive Metastore的uris。
使用hadoop用户,不然不能创建logs目录权限
/usr/local/spark/sbin/start-thriftserver.sh --master yarn --queue hainiu

使用任意业务用户来使用beeline连接thriftserver
/usr/local/hive/bin/beeline
这是使用了hive的beeline,因为与sparkserver提供的jdbc版本不一致所以,提示这个错误
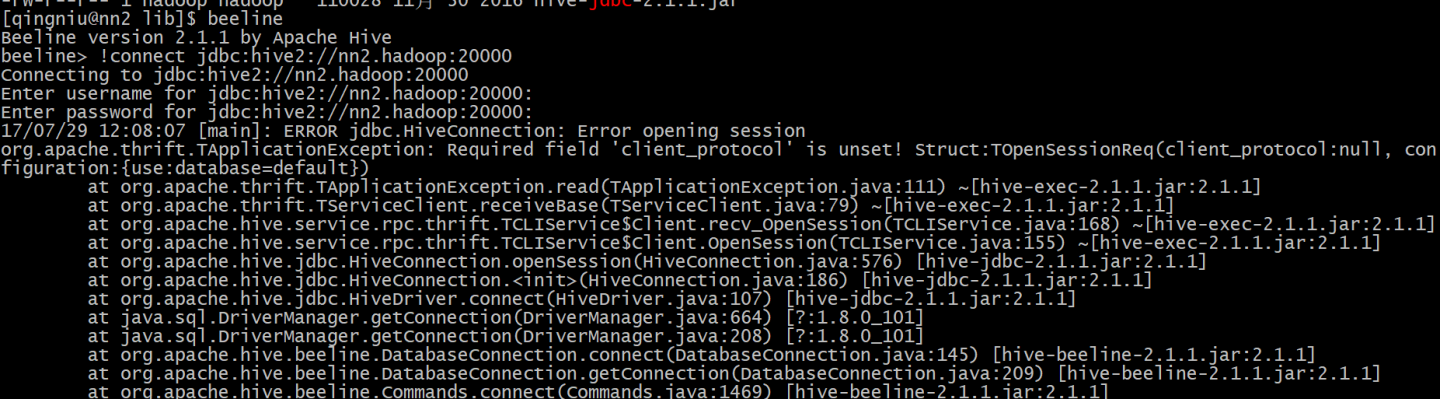
/usr/local/spark/bin/beeline
!connect jdbc:hive2://nn2.hadoop:20000
用spark的beeline就可以连接成功,因为使用的版本是一致的

缓存表,内存不够就刷到硬盘
cache table user_install_status;
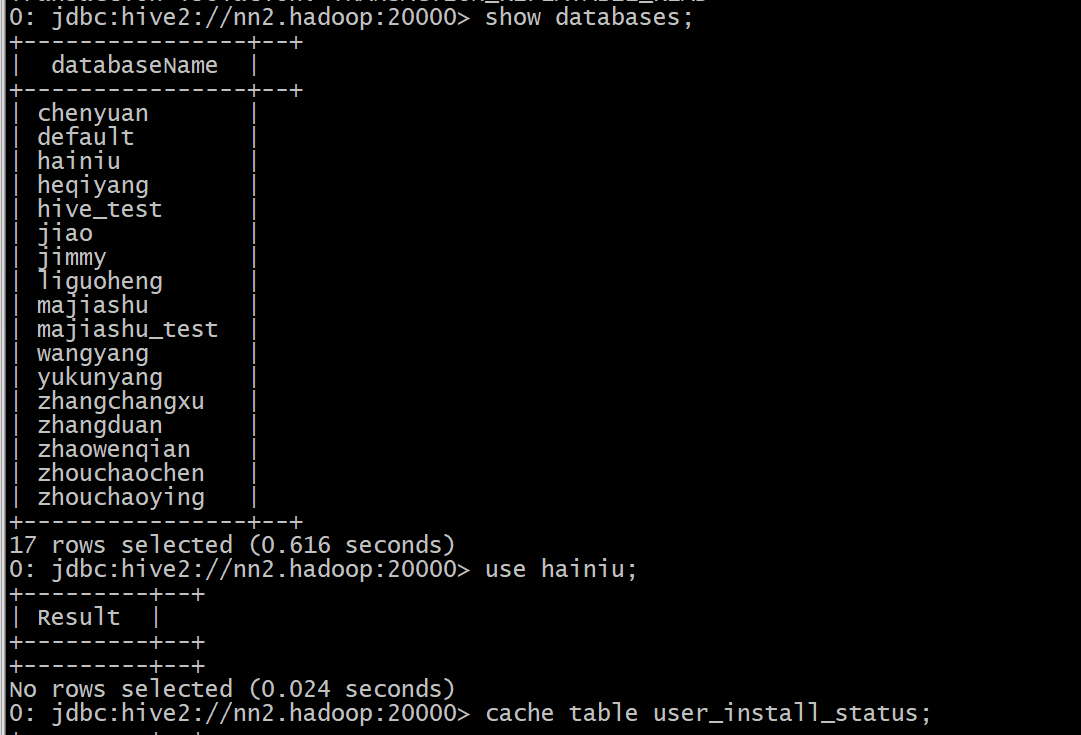

这时数据缓存在硬盘,查询用时30秒

可以调大thriftserver的executor缓存和executor数量 --num-executors 12 --executor-memory 5G
/usr/local/spark/sbin/start-thriftserver.sh --master yarn --queue hainiu --num-executors 12 --executor-memory 5G



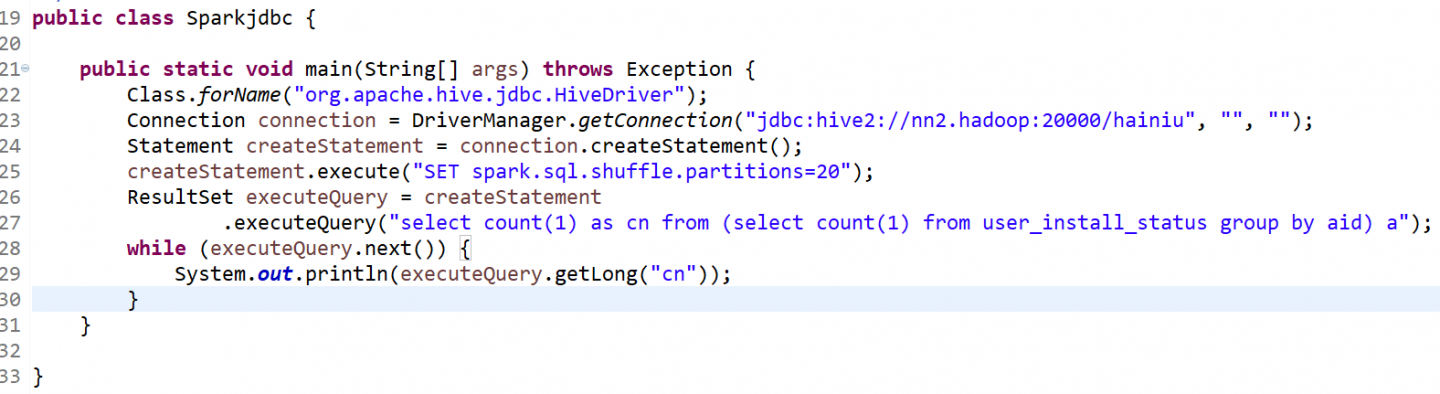
5.spark-jdbc编程#通过JDBC连接thriftserver
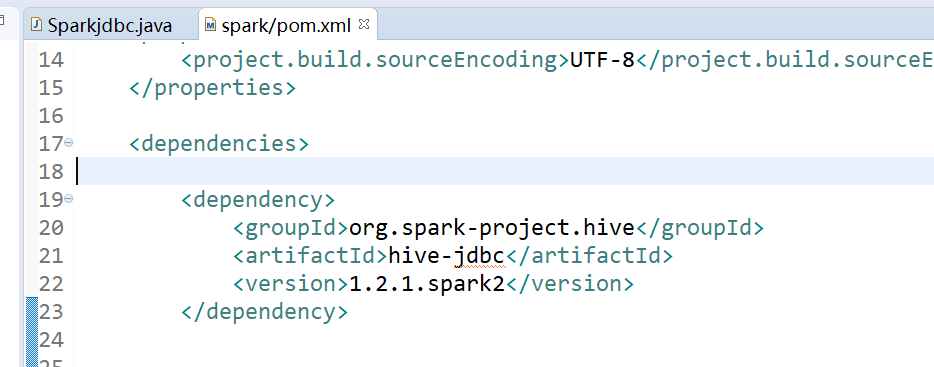
pom里添加spark的hive-jdbc


 发表于 2018-3-16 14:15:07
发表于 2018-3-16 14:15:07

